

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
AllAgricultureAutonomousComputer VisionCybersecurityE-commerceFoodGeospatial technologyIndustrial AutomationMedicalNLPOCRRetailSEOSportsWildlife Biology


Sentiment and Emotion Detection for Social LLMs
Sentiment and Emotion Detection for Social LLMs Project Overview: Objective The goal was to develop a dataset that improves LLMs’ […]
Read More →
Code Commenting and Explanation for LLM-based Coders
Code Commenting and Explanation for LLM-based Coders Project Overview: Objective The goal was to develop a dataset that would enhance […]
Read More →
Conversational Context Understanding for LLM-based Chatbots
Conversational Context Understanding for LLM-based Chatbots Project Overview: Objective The goal was to develop a dataset that would train and […]
Read More →

Recipe Annotation for Food & Beverage LLM
Recipe Annotation for Food & Beverage LLM Project Overview: Objective The goal was to create a detail dataset that enhances […]
Read More →
Customer Feedback Analysis for Financial Services LLM
Customer Feedback Analysis for Financial Services LLM Project Overview: Objective The goal was to build a comprehensive dataset of customer […]
Read More →
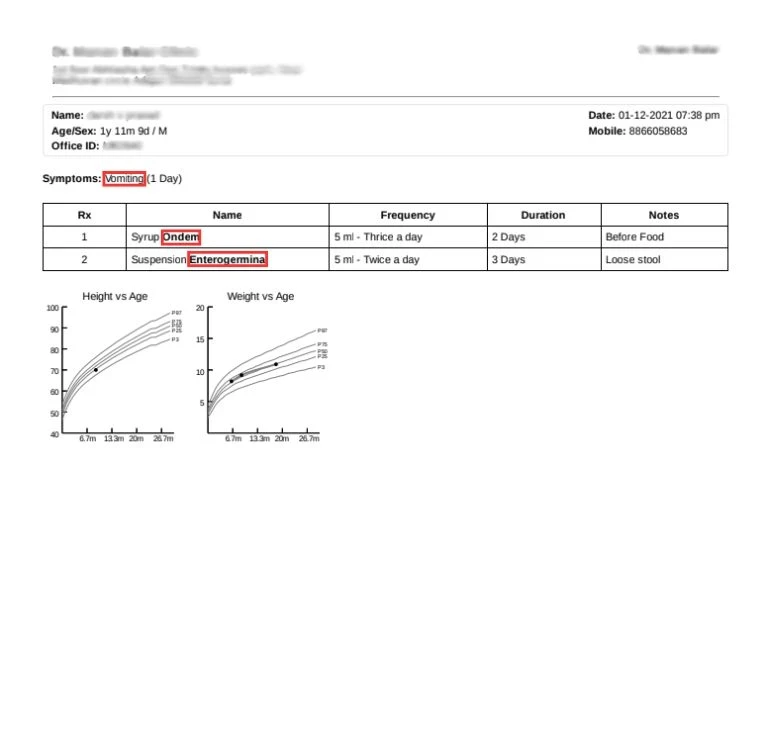
Medical Record Annotation for Healthcare LLM
Medical Record Annotation for Healthcare LLM Project Overview: Objective The objective of this project was to develop a comprehensive dataset […]
Read More →

Product Categorization for Retail LLM
Product Categorization for Retail LLM Project Overview: Objective The goal is to build a comprehensive dataset that enables LLMs to […]
Read More →Interactive Preference Collection for Conversational AI
Interactive Preference Collection for Conversational AI Project Overview: Objective The objective was to gather a vast dataset comprising multi-turn conversations […]
Read More →
Image Description for Generative AI
Image Description for Generative AI Project Overview: Objective The aim was to produce a comprehensive dataset of 100,000 images paired […]
Read More →
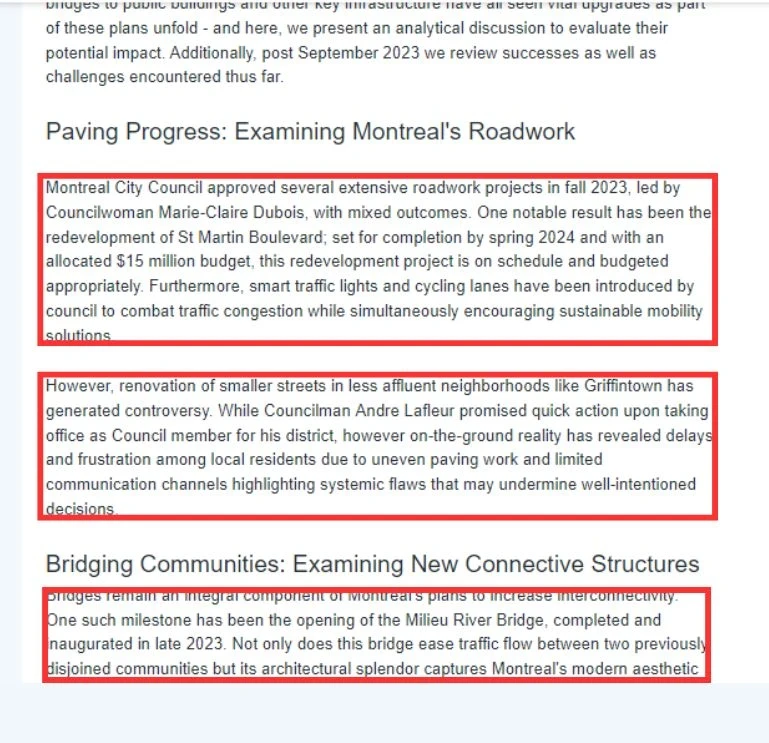
Question and Answer Annotation
Question and Answer Annotation Project Overview: Objective The primary objective was to build a dataset that could effectively enhance the […]
Read More →

Remote Sensing Image Dataset
Conclusion
EuroSAT is a vital tool for improving research and applications in remote sensing and Earth observation.
Read More →

Image Annotation for Retail Inventory Management
The “Image Annotation for Retail Inventory Management” dataset is a valuable asset for the retail industry
Read More →