
Question and Answer Annotation
Home » Case Study » Question and Answer Annotation
Project Overview:
Objective
The primary objective was to build a dataset that could effectively enhance the question-answering capabilities of LLMs across various domains by providing them with high-quality, annotate articles, questions, and answers.
Scope
The dataset enclose a bunch of matters, like news, education, and company policies. It is made to reproduce real-life question-answering circumstances, offering an overall resource for LLMs training to comprehend and generate exact responses.

Sources
- Synthetic Articles: A dedicate team of content writers generate 20,000 synthetic articles covering multiple categories like news, education, company policies, and more.
- Non-Synthetic Articles: The project also included real articles sourced from various credible platforms to add diversity and realism to the dataset.

Data Collection Metrics
- Total Articles Generated: 20,000 articles were created and sourced.
- Questions Annotated: 100,000 questions were formulated based on article summaries.
Annotation Process
Stages
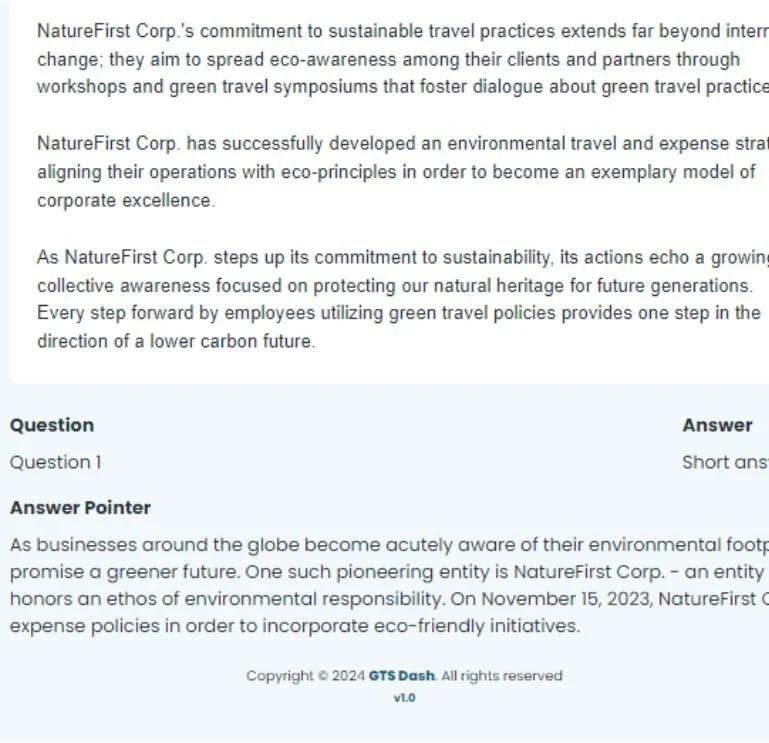
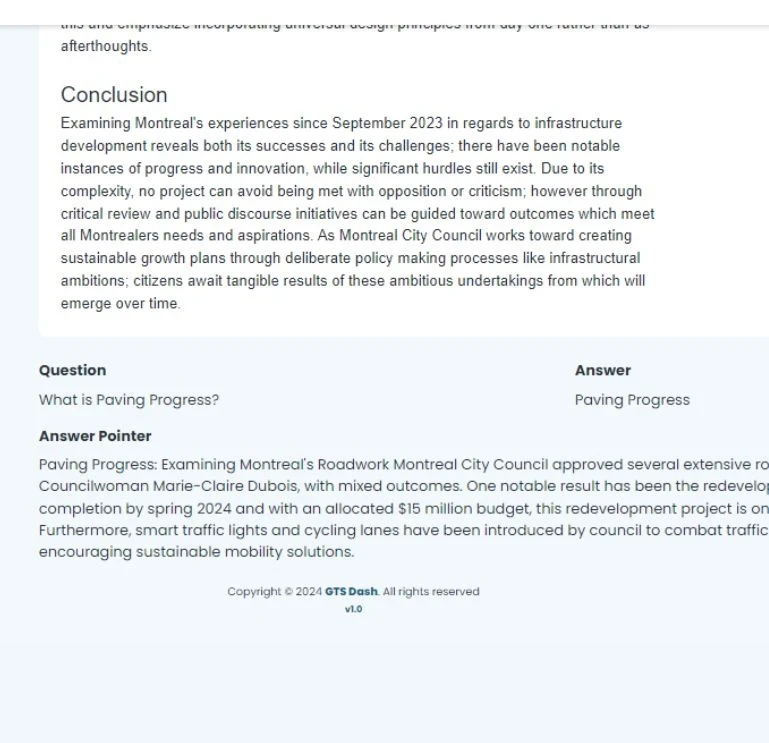
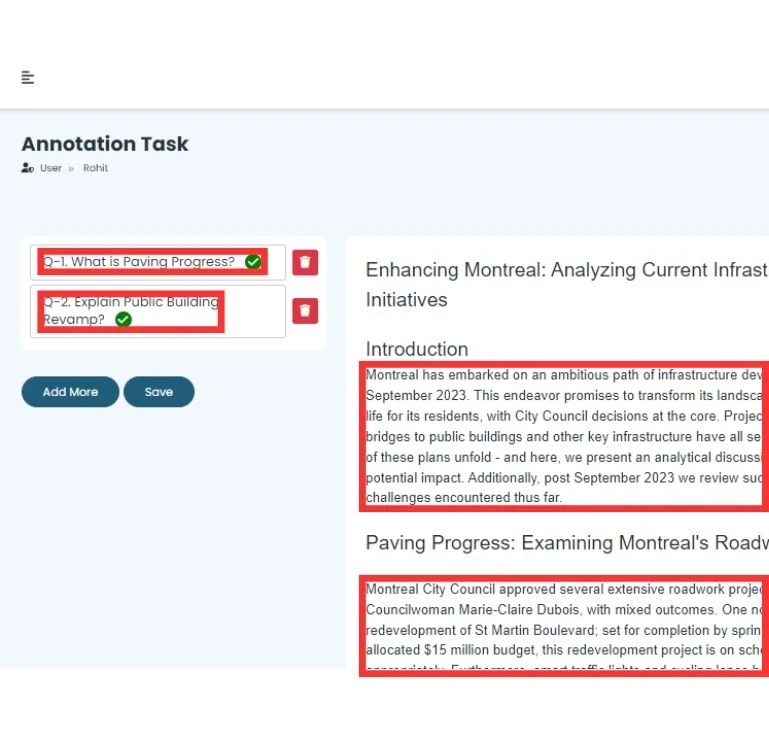
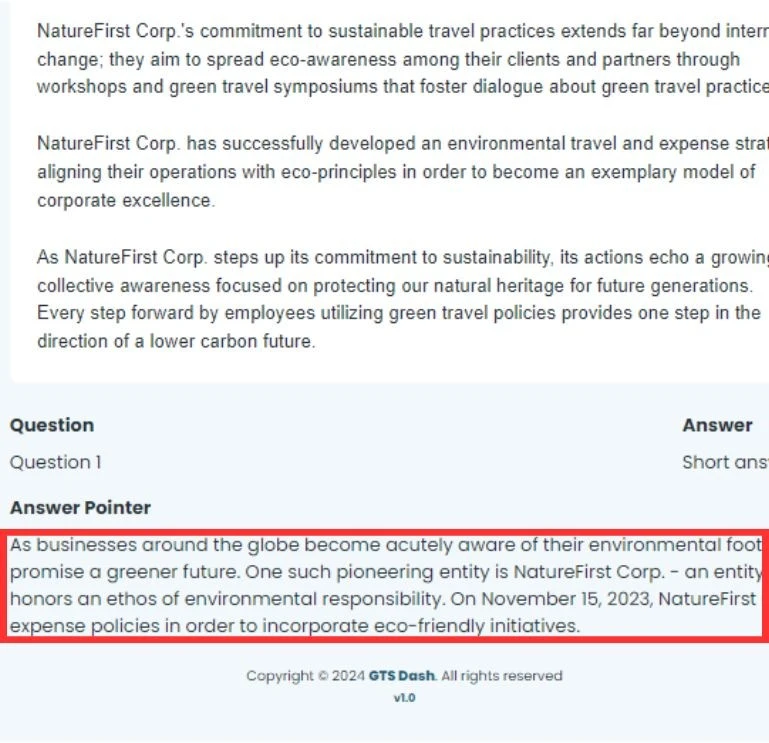
- Question Annotation: A specialized team of annotators accessed article summaries to frame five questions per article, resulting in 100,000 questions. These questions were designed to test the model’s ability to understand and generate accurate responses.
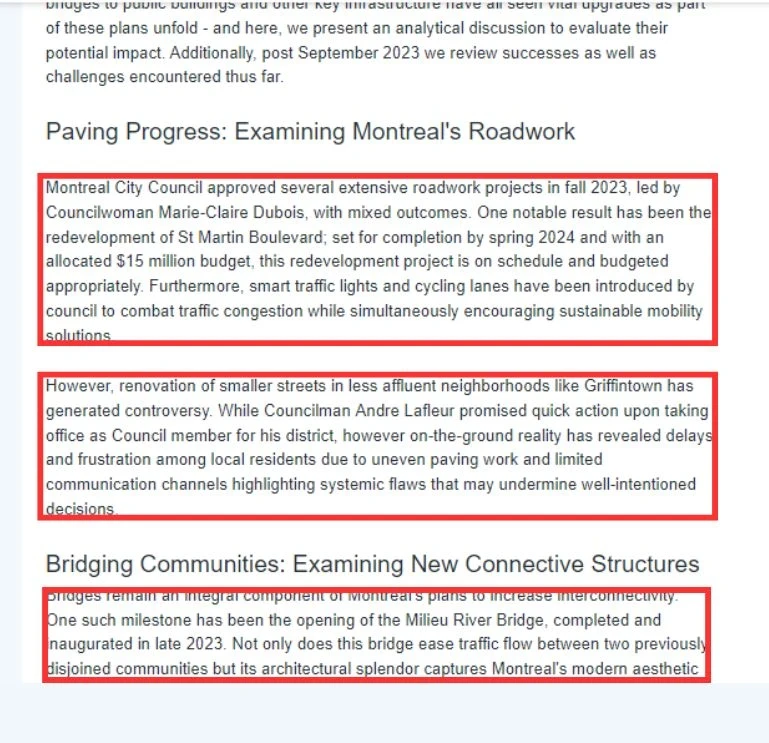
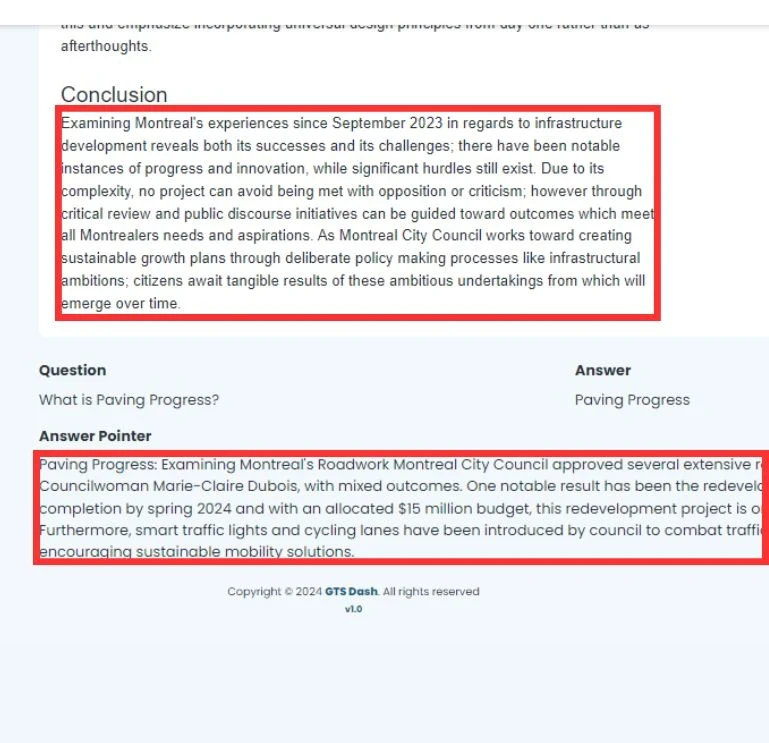
- Answer Annotation: Another team of annotators, with access to the full articles, provided precise answers to each question and marked the relevant paragraphs where the answers were found. This ensured that the dataset was not only comprehensive but also aligned with real-world applications.
Annotation Metrics
- Total Questions Annotated: 100,000 questions were annotated, ensuring each article had a corresponding set of questions to train LLMs effectively.
- Total Answers Annotated: 100,000 answers were annotated, with accurate paragraph markings to enhance the training quality for LLMs.
Quality Assurance
Stages
- Accuracy and Consistency: Throughout the project, continuous checks and model testing were performed to maintain high levels of accuracy in both question formulation and answer annotation.
- Data Integrity: Strict protocols were followed to ensure that all annotations were consistent, reliable, and accurately reflected the content of the articles.
- Feedback Loop: A feedback system was implemented to improve the dataset continuously based on preliminary testing and model performance.
QA Metrics
- Question Framing Accuracy: The accuracy of the questions framed based on article summaries was maintained at a high standard, ensuring relevance and clarity.
- Answer Precision: The precision in marking the correct paragraphs for the answers was rigorously checked, achieving a high level of accuracy.
Conclusion
The creation of this extensive dataset, with 20,000 articles, 100,000 questions, and 100,000 annotated answers, marks a significant advancement in the training and evaluation of LLMs for question-answering tasks. This dataset provides a rich resource for improving the performance of LLMs across a wide range of topics, making them more capable of understanding and responding to questions in real-world scenarios.

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
Let's Discuss your Data collection Requirement With Us
To get a detailed estimation of requirements please reach us.