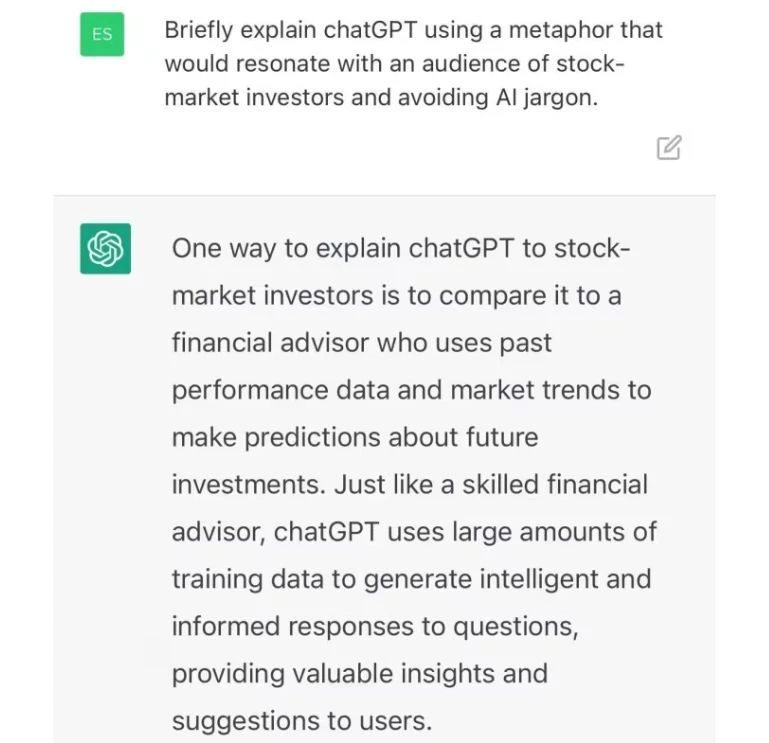
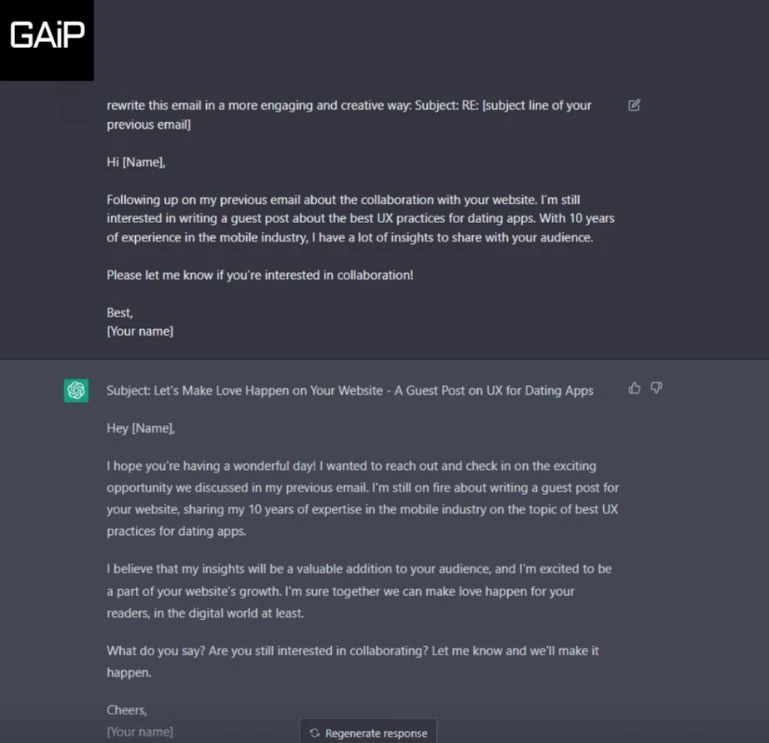
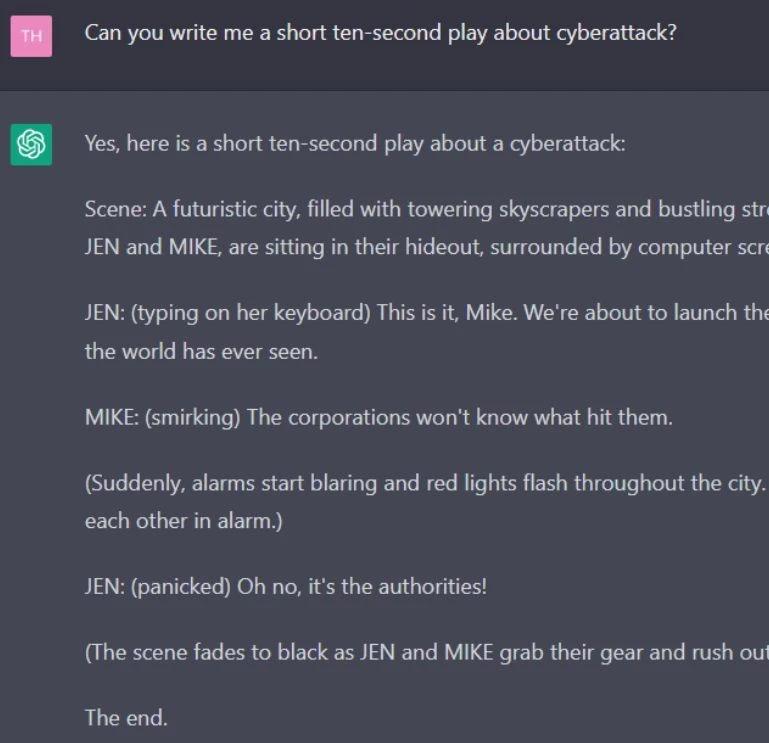
The dataset includes synthetic multi-turn conversations across a range of scenarios, such as customer support, casual chatting, and information retrieval. Each conversation is annotate to highlight key context points and conversational shifts, aiding the LLM in maintaining context.