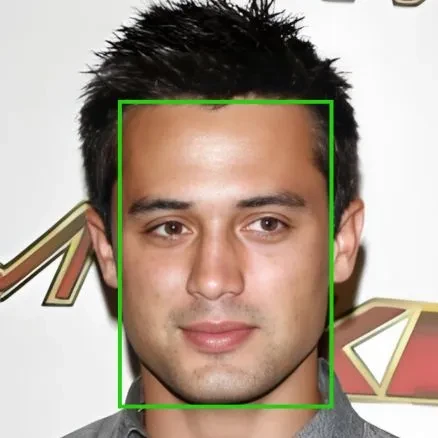
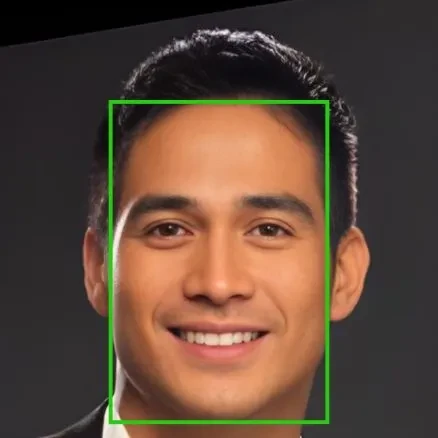
The Facial Attribute Dataset – CelebA encompasses an extensive array of facial characteristics, including gender, age, facial expressions, presence of accessories, and ethnicity, among others. Moreover, this dataset captures the complexity of real-world scenarios by incorporating diverse lighting conditions, variations in facial orientations, and instances of occlusions. Consequently, it simulates a broad spectrum of real-life situations, providing a robust and comprehensive resource for training and testing facial attribute recognition algorithms.