
TextOCR – Text Extraction from Images Dataset
Home » Dataset Download » TextOCR – Text Extraction from Images Dataset
TextOCR – Text Extraction from Images Dataset
Datasets
TextOCR – Text Extraction from Images Dataset
File
TextOCR – Text Extraction from Images Dataset
Use Case
Document digitization
Description
Text OCR (Optical Character Recognition) is a technology that enables the extraction of text content from images or scanned documents. To develop and train Text OCR systems, specialized datasets are created. These datasets play a crucial role in training, evaluating, and fine-tuning OCR models.
About Dataset
At our AI data collection company, we’re committed to pushing the limits of artificial intelligence and data processing. Our most recent initiative focuses on developing a valuable asset known as the TextOCR – Text Extraction from Images Dataset.

In our pursuit of AI excellence, we recognize the significance of top-quality data. This dataset underscores our dedication to equipping the AI community with essential resources for creating cutting-edge text extraction models and applications.
Discover more about the data on our website: TextOCR – Text Extraction from Images Dataset.
Our dataset is carefully curated, offering a wide range of challenging scenarios for extracting text from images.
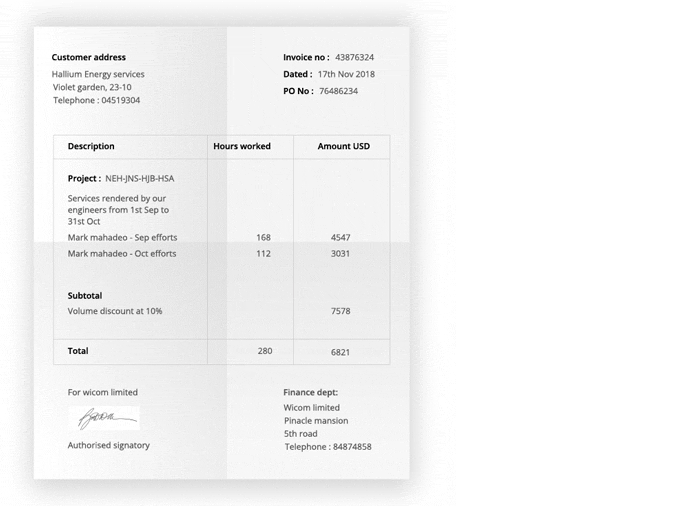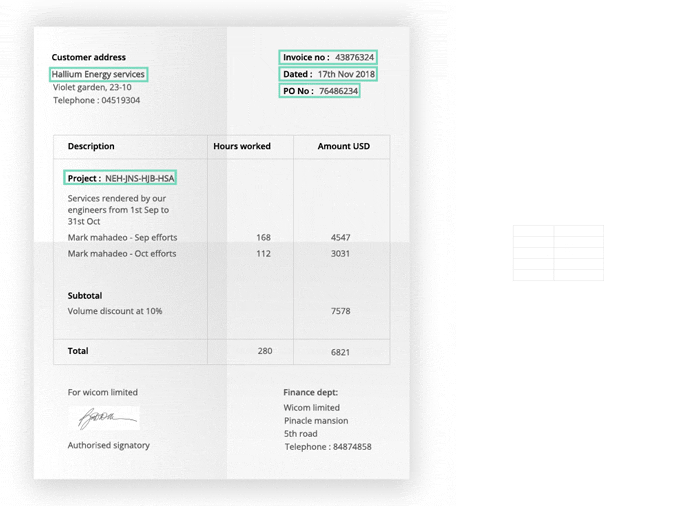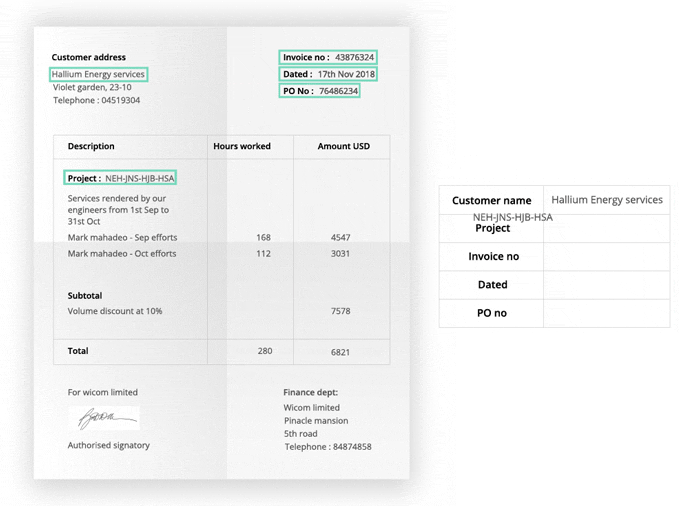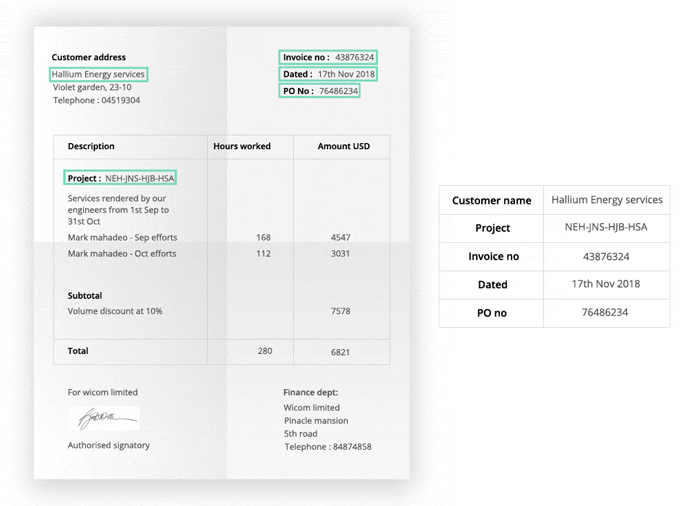
Key Highlights of the TextOCR Dataset:
Versatile Data: Our dataset includes a wide variety of images, making it useful for different fields like finance, healthcare, and more.
Accuracy and Diversity: We’ve made sure to include images with different levels of difficulty, fonts, languages, and text sizes. This ensures that your OCR models can handle real-world situations effectively.
Annotated Ground Truth: Each image in the TextOCR dataset comes with detailed annotations, making it perfect for training and testing OCR algorithms.
Community Collaboration: We believe in collaboration within the AI community. By sharing this dataset, we hope to inspire new ideas and facilitate knowledge sharing among AI enthusiasts, researchers, and developers.
Join us on this journey of innovation and exploration as we dive into the world of TextOCR and text extraction from images. Visit our dedicated page to access the data and start leveraging the power of AI in text extraction
At our AI data collection company, we’re not just collecting data; we’re shaping the future of AI. Discover the possibilities today!
Conclusion
Globose Technology Solutions Private Limited is a leader in TextOCR, offering a top-notch solution for extracting text from image datasets. Our advanced technology ensures high accuracy, making data extraction faster and more efficient across different industries. Globose Technology Solutions continues to lead the way in groundbreaking technologies, providing a powerful and innovative tool for transforming text extraction from images.
This dataset is sourced from gts.ai.
Contact Us

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
Let's Discuss your Data collection Requirement With Us
To get a detailed estimation of requirements please reach us.