
Name Entity Recognition Dataset
Home » Case Study » Name Entity Recognition Dataset
Project Overview:
Objective
The primary goal of this project was to develop a robust Named Entity Recognition (NER) dataset. This dataset aims to facilitate advanced text analysis by identifying and categorizing named entities in various texts, enhancing applications in fields like information retrieval, content classification, and natural language processing.
Scope
Our project encompassed the creation and refinement of a comprehensive NER dataset. This included sourcing, collection, and annotation of diverse text data, ranging from news articles and academic papers to social media posts and corporate documents.
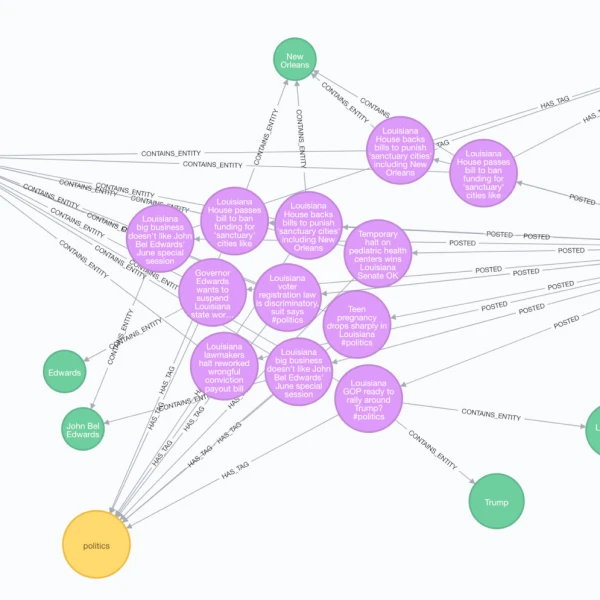


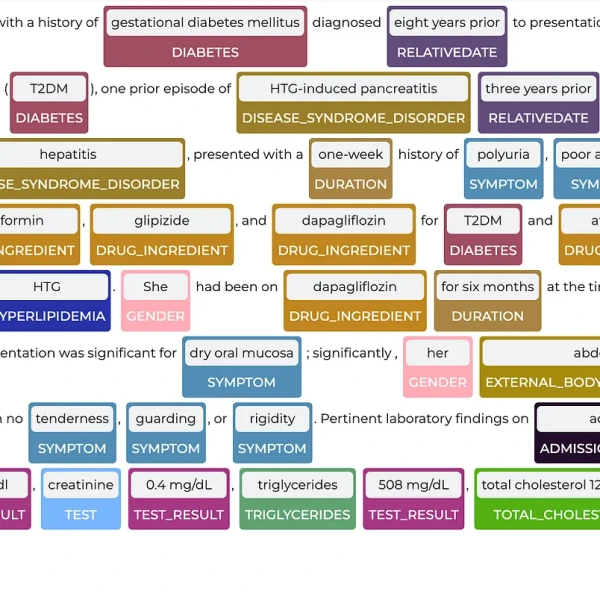
Sources
- News Articles: A vast collection of articles from various global news outlets, covering a range of topics and events.
- Academic Papers: An extensive set of documents from multiple disciplines, ensuring a rich vocabulary and complex entity structures.

Data Collection Metrics
- Total Data Points:Over 2 million text documents, encompassing a broad spectrum of topics and styles.
- Data Diversity: Careful selection to ensure a wide range of domains, languages, and formats, covering over 500 distinct themes.
Annotation Process
Stages
- Data Preprocessing:Standardizing and cleaning text data to ensure uniformity and readability.
- Entity Identification: Rigorous process of identifying named entities such as people, organizations, locations, dates, and specialized terms.
- Categorization and Tagging: Assigning specific tags to each identified entity, adhering to a predefined NER schema.
Annotation Metrics
- Entities Annotated:Over 10 million named entities accurately tagged.
- Annotation Accuracy:Striving for an accuracy rate above 98%, validated through multiple quality checks.
Quality Assurance
Stages
Expert Review: Involvement of linguists and domain experts to verify a subset of annotations for accuracy and consistency.
Continuous Refinement: Ongoing process to refine the dataset based on evolving language trends and user feedback.
Feedback Integration: Implementing a system for continuous input from users to improve and update the dataset.
QA Metrics
- Expert Review Cases:Approximately 15% of the dataset subjected to expert review.
- Annotation Quality Improvement:Regular assessment of annotation precision and recall, with continuous enhancements
Conclusion
The NER Dataset project marks a significant milestone in our commitment to advancing text analysis and natural language processing. By providing a meticulously curated and annotated dataset, we enable researchers, developers, and businesses to unlock deeper insights from text data, fostering innovation and efficiency in various applications.

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
Let's Discuss your Data collection Requirement With Us
To get a detailed estimation of requirements please reach us.