
New Zealand English General Conversation Dataset
Home » Case Study » New Zealand English General Conversation Dataset
Project Overview:
Objective
We embarked on a mission to curate a valuable dataset that facilitates the development of advanced AI models capable of understanding and generating natural language. Consequently, our project, titled “New Zealand English General Conversation Dataset,” aimed to create a comprehensive resource for the AI community. Ultimately, this dataset serves as a foundation for training machine learning models, enabling them to understand and generate natural-sounding conversations in the unique context of New Zealand English.
Scope
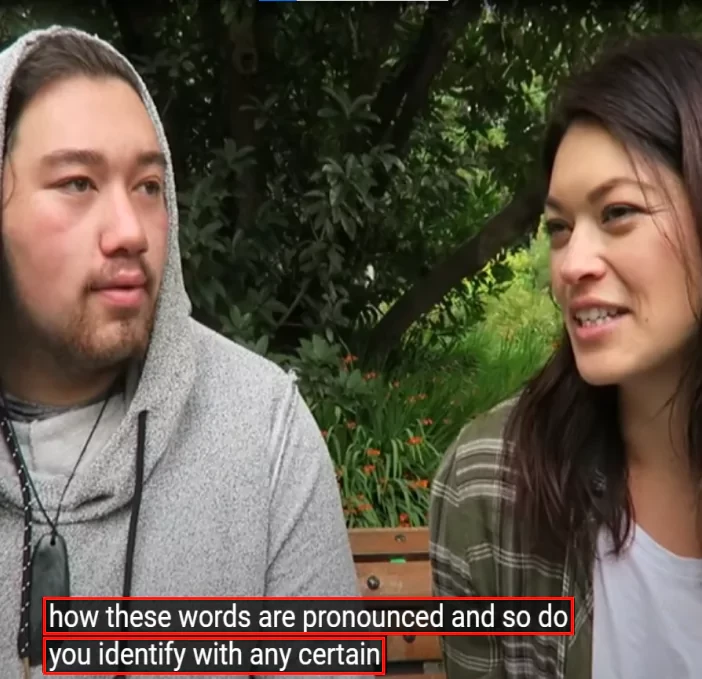
Our project involved collecting and annotating conversations in New Zealand English across various domains, including everyday conversations, cultural nuances, and regional expressions. Additionally, we strived to capture the richness and diversity of New Zealand English to enable AI models to engage in more contextually relevant and meaningful conversations.




Sources
- To compile this dataset, we tapped into a wide range of sources:
- Recorded Conversations: We collected audio recordings of real conversations between New Zealanders in different settings, thereby ensuring a broad representation of topics and regional dialects.
- Transcriptions: Skilled linguists and language experts transcribed the conversations, thereby ensuring the authenticity of spoken New Zealand English is preserved.
- Textual Data: We sourced written texts, such as interviews, social media conversations, and online forums, to further enrich the dataset with written expressions of New Zealand English. Moreover, we incorporated these diverse sources to enhance the breadth and depth of the dataset.


Data Collection Metrics
- Total Conversations Collected: 25,000 conversations
- Recorded Conversations: 12,000
- Transcribed Conversations: 8,000
- Textual Data: 5,000
Annotation Process
Stages
- Conversation Segmentation: Our annotation team meticulously segmented each conversation into meaningful units, thereby ensuring the dataset’s usability. Additionally, they employed careful attention to detail, enhancing the overall quality of the annotations.
- Speaker Identification: We annotated speakers in multi-party conversations to facilitate dialogue generation tasks, thereby enhancing the coherence and fluidity of the generated dialogues.
- Transcription Correction: We annotated speakers in multi-party conversations to facilitate dialogue-generation tasks by identifying speakers and their respective utterances. Consequently, this process streamlines the dialogue-generation tasks, ensuring clarity and coherence in the generated conversations.
- Regional Markers: We tagged regional markers and colloquialisms in order to capture the nuances of New Zealand English. Thus, ensuring a comprehensive understanding of the language’s unique characteristics.
- Emotion Annotation: Sentiment and emotional tone were annotated, thus enabling emotion-aware AI models to comprehend the nuances of human expression effectively.
Annotation Metrics
- Conversations with Annotations: 25,000
- Speaker Identifications: 50,000
- Transcription Corrections: 10,000
- Regional Markers Tagged: 5,000
- Emotion Annotations: 15,000


Quality Assurance
Stages
Our commitment to data quality and integrity was unwavering throughout the project:
- Annotation Verification: Subject matter experts reviewed and, moreover, verified the accuracy and authenticity of the annotations.
- Data Quality Control: Additionally, Data Quality Control measures were implemented to rigorously eliminate irrelevant or low-quality data.
- Data Security: Moreover, we upheld the highest standards of Data Security, adhering to copyright and privacy regulations.
QA Metrics
- Annotation Validation Cases: 2,500 (10% of total)
- Data Cleansing: Removal of irrelevant or low-quality data
Conclusion
The “New Zealand English General Conversation Dataset” is a pivotal resource for researchers, AI developers, and language enthusiasts. This meticulously curated dataset, comprising a rich tapestry of conversations and annotations, empowers AI models to converse naturally in the distinctive New Zealand English dialect. It opens new avenues for AI applications, from chatbots with regional flair to language learning tools tailored to New Zealand English. Additionally, this dataset is a testament to our dedication to fostering linguistic diversity in AI and driving innovation in natural language understanding.

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
Let's Discuss your Data collection Requirement With Us
To get a detailed estimation of requirements please reach us.