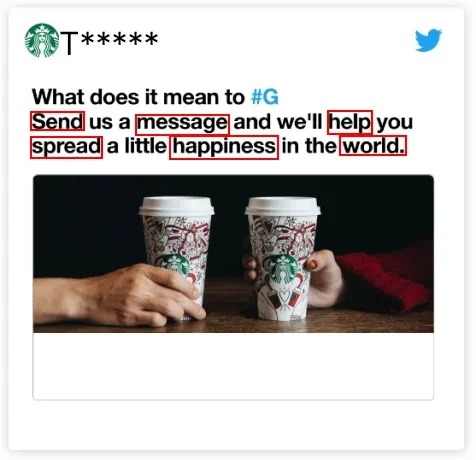
The “Keyword Extraction for Trend Analysis” dataset is a powerful resource for trend analysis, market research, and insights generation across diverse domains. With a vast collection of text data, accurate keyword annotations, and robust privacy and security measures, this dataset empowers analysts, researchers, and businesses to stay ahead of emerging trends and gain deeper insights into various subjects. It serves as a foundation for developing advanced trend analysis and text mining solutions that can inform decision-making and strategy development in an ever-evolving landscape of information and trends.