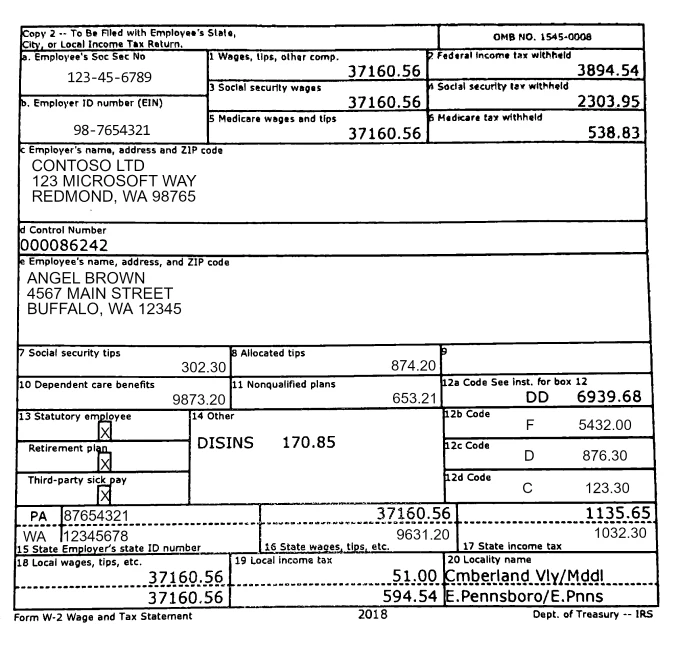
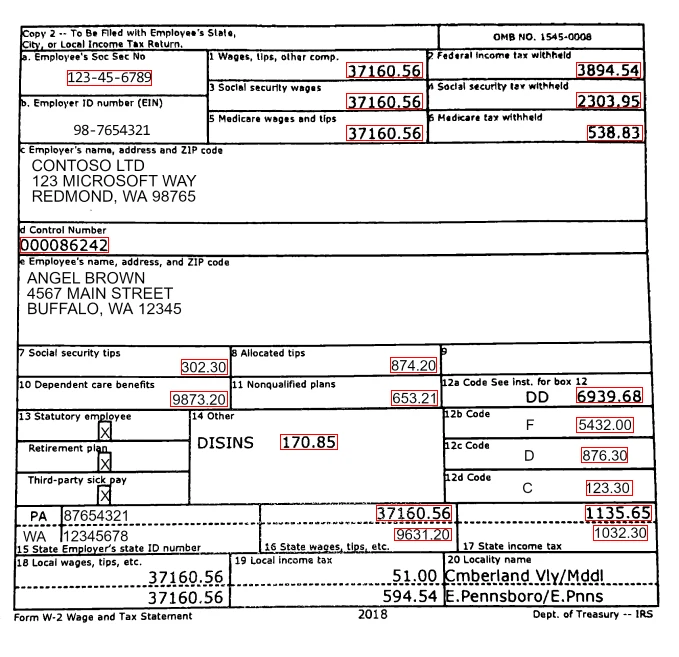
The Insurance Dataset project is an extensive initiative focused on collecting and analyzing insurance-related data from various sources. This project aims to create a comprehensive dataset that captures a wide array of insurance domains, including health, auto, life, and property insurance.
Scope
The project encompasses data from numerous insurance types and covers various aspects such as claim histories, policy details, customer interactions, and risk profiles. The dataset includes both structured and unstructured data, providing a holistic view of the insurance industry.
Sources
Data is collected from a variety of sources, including insurance companies, online platforms, customer surveys, and claim databases. All data collection complies with privacy laws and ethical standards, ensuring data integrity and confidentiality.
Geographical Coverage: 30 countries, with a focus on North America, Europe, and Asia
Data Types: Policy details, claim records, customer profiles, risk assessments
Annotation Process
Stages
Data Categorization: Organizing data by insurance type, region, and policy details.
Risk Factor Analysis: Annotating data with risk factors and historical claim information.
Customer Feedback Tagging: Integrating customer satisfaction scores and feedback.
Annotation Metrics
Total Records Annotated: 500,000
Unique Annotations: 2,500,000
Average Annotations per Record: 5
Quality Assurance
Stages
Objective: Ensure the dataset remains accurate and relevant to the insurance industry’s evolving needs. Activities: Periodically reassess and update the dataset to reflect changes in insurance policies, emerging trends in risk factors, and updates in regulatory requirements. This stage involves re-evaluating the existing data for relevance and accuracy, adding new data as industry practices evolve, and refining data categorization.
QA Metrics
Data Accuracy: 99%
Annotation Consistency: 98%
Completeness of Risk Factor Analysis: 97%
Conclusion
Our Insurance Dataset project stands as a testament to our commitment and capability in creating high-quality, industry-specific datasets for machine learning. This project has set a new standard in the insurance industry, offering unprecedented improvements in processing efficiency, fraud detection accuracy, and overall operational effectiveness.
Quality Data Creation
Guaranteed TAT
ISO 9001:2015, ISO/IEC 27001:2013 Certified
HIPAA Compliance
GDPR Compliance
Compliance and Security
Let's Discuss your Data collection
Requirement With Us
To get a detailed estimation of requirements please reach us.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.