
Code Commenting and Explanation for LLM-based Coders
Project Overview:
Objective
The goal was to develop a dataset that would enhance LLMs’ understanding of code logic, functions, and potential edge cases, thereby improving their utility in generating high-quality code comments and explanations for developers.
Scope
The dataset includes a diverse collection of code snippets from various programming languages and domains. Each snippet is annotated with detail explanations covering the logic, functionality, and potential edge cases, providing the LLM with the context needed to generate accurate and helpful comments.
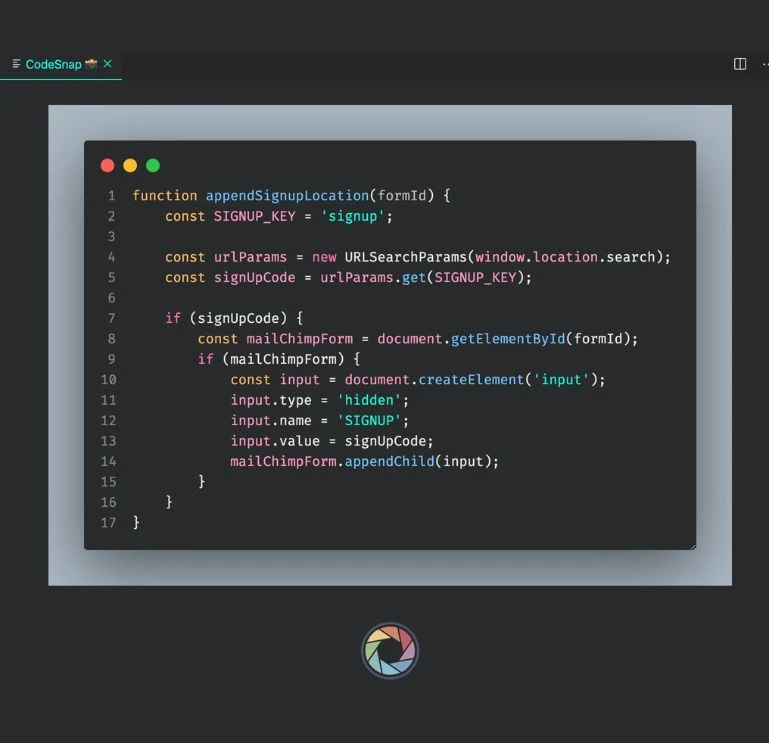
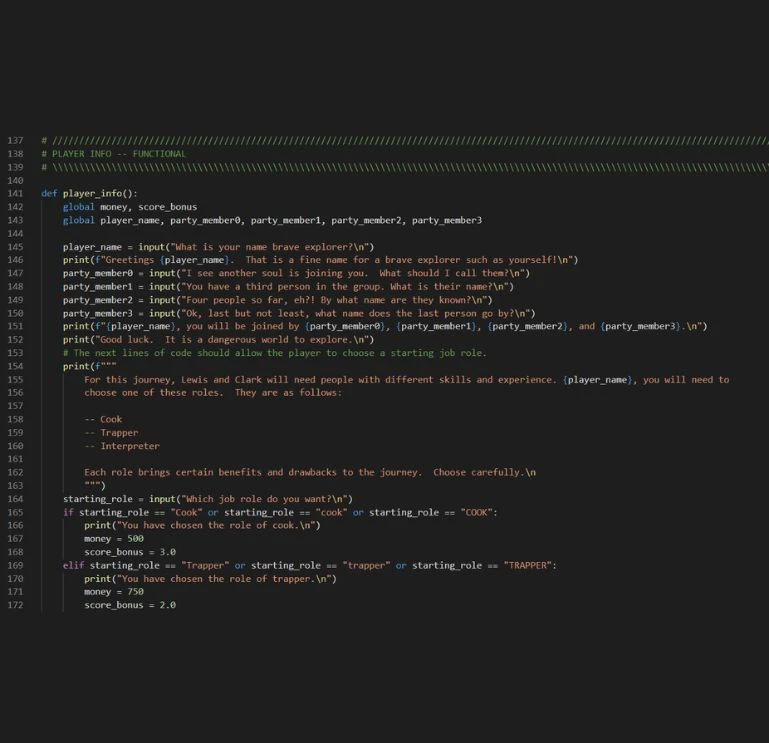
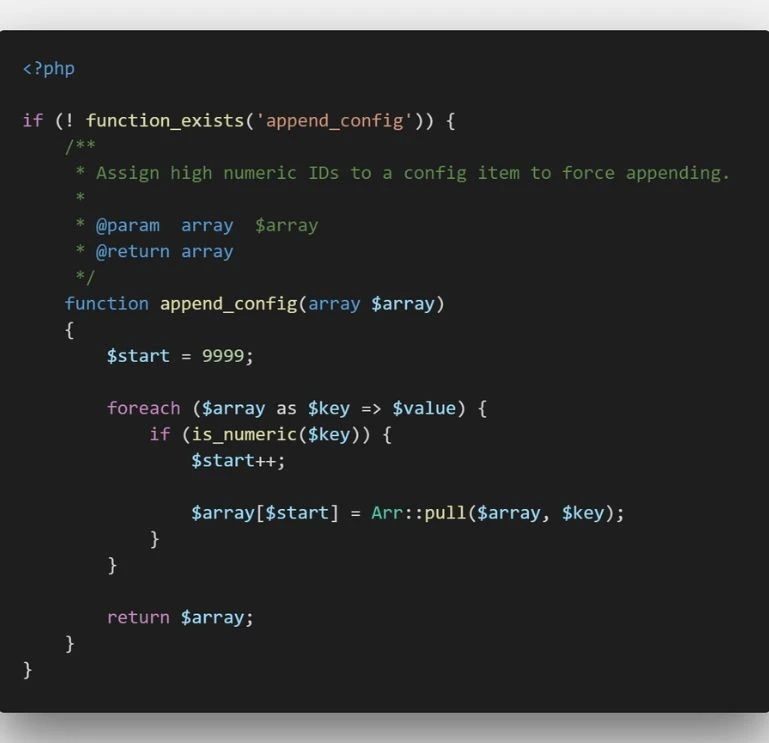
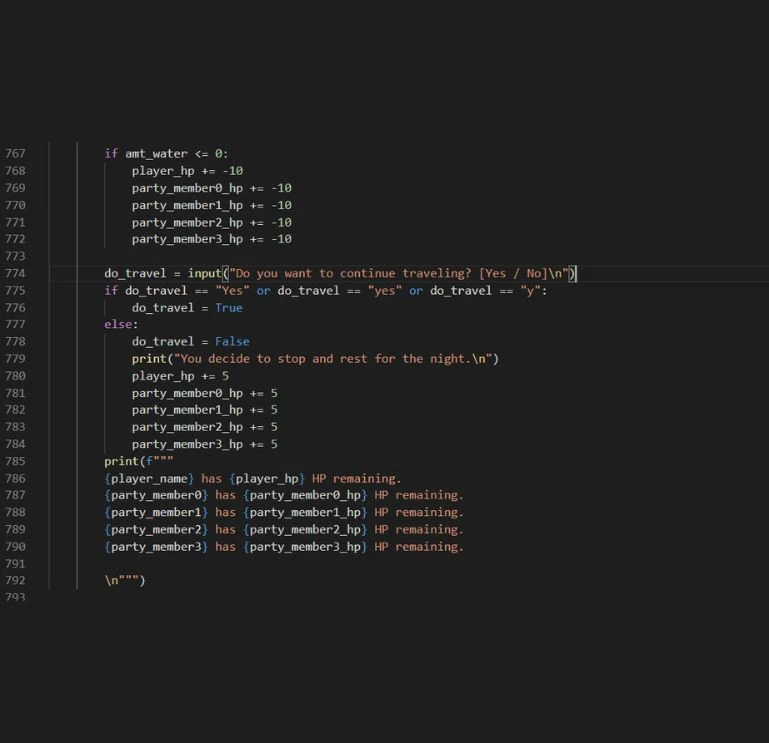
Sources
- Code Collection: A total of 100,000 code snippets were collect from a variety of programming languages and domains, ensuring broad coverage of coding practices and use cases.

Data Collection Metrics
- Total Code Snippets Collected: 100,000 code snippets.
- Explanations Provided: 100,000 detailed explanations, with an average length of 50 words per explanation.
Annotation Process
Stages
- Expert Annotations: A team of 50 annotators with expertise in software development provided detail explanations for each code snippet. These explanations cover the logic, functionality, and potential edge cases to ensure comprehensive understanding.
- Contextual Relevance: Annotations were design to be contextually relevant, helping the LLM grasp the nuances of each code snippet and generate appropriate comments.
Annotation Metrics
- Team Involvement: A team of 50 annotators, all experience software developers and engineers, work over a period of 4 months to complete the project.
- Total Annotations: 100,000 explanations were provided, ensuring that each code snippet was thoroughly explained.
Quality Assurance
Stages
- Annotation Accuracy: Rigorous quality checks were implemented to ensure that the explanations were accurate, detailed, and contextually appropriate.
- Consistency Reviews: Regular reviews were conducted to maintain consistency across all annotations, ensuring that the dataset was reliable and effective for training LLMs.
QA Metrics
- Explanation Accuracy: High accuracy was achieved in providing detailed and contextually relevant explanations for each code snippet.
- Consistency in Annotations: The dataset maintained a high level of consistency across annotations, contributing to the reliability of the LLM’s training data.
Conclusion
The creation of this code commenting and explanation dataset significantly enhanced the ability of LLMs to understand and generate accurate code explanations. This improvement has proven valuable for developers, enabling more effective use of LLM-base coding tools and improving the quality of auto-generate code comments.

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
Let's Discuss your Data collection Requirement With Us
To get a detailed estimation of requirements please reach us.