
Chinese Natural Language Understanding Dataset
Home » Case Study » Chinese Natural Language Understanding Dataset
Project Overview:
Objective
Constructing a comprehensive dataset is crucial for enhancing the accuracy and effectiveness of Natural Language Understanding (NLU) models when it comes to processing and comprehending the Chinese language. This dataset serves as a foundational element for advancements in various AI-driven linguistic applications tailored specifically for Chinese speakers. By incorporating a diverse range of transition words, we can further refine and enrich the dataset, thus facilitating more nuanced and contextually appropriate language comprehension by NLU models.
Scope
Collecting written content across diverse domains like news, fiction, social media, scientific articles, and everyday conversations can provide valuable insights. Each entry will be associated with annotations to capture sentiment, intent, entities, and context. Moreover, in news articles, journalists often aim to present factual information in an objective manner.

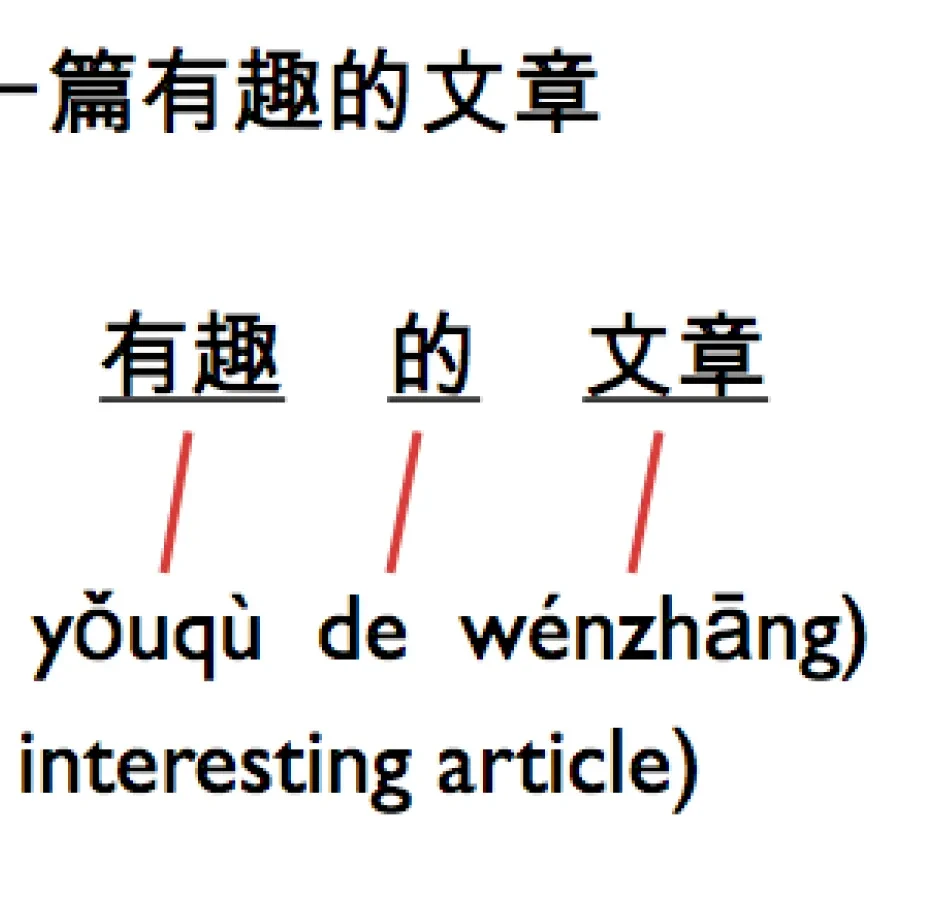


Sources
- Chinese news agencies and publishers have established partnerships, resulting in a meticulously collected array of content. Moreover, this collaboration has facilitated acquiring diverse perspectives and insights. Additionally, these alliances have fostered a deeper understanding of Chinese culture and society.
- Extracts derived from popular Chinese literature, carefully curated for a comprehensive representation.
- Collaborations have been established with universities in order to gather a comprehensive collection of academic papers and theses. Additionally, these partnerships facilitate the acquisition of valuable research material. Moreover, by working closely with academic institutions, we are able to access a wide array of scholarly publications.
- Mining of public social media posts, forums, and blogs is conducted with proper consent and anonymization, thus resulting in a thoughtfully collected dataset. Additionally, various transition words can be added to enhance the coherence of the content.

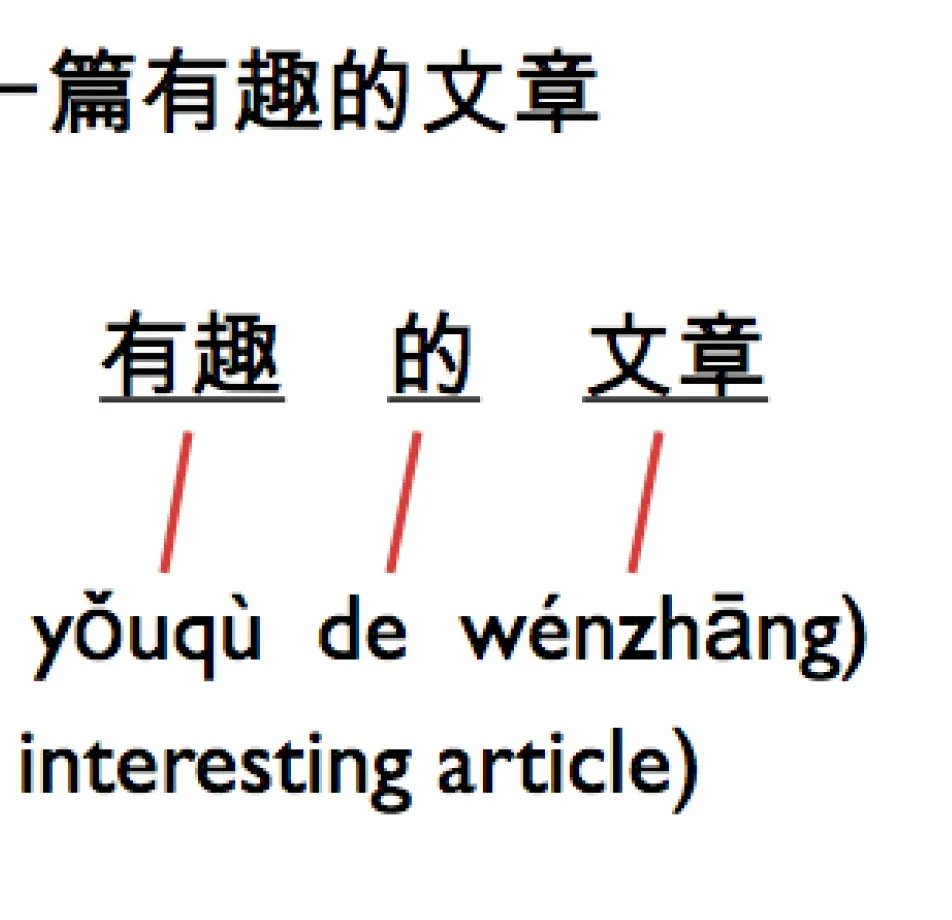
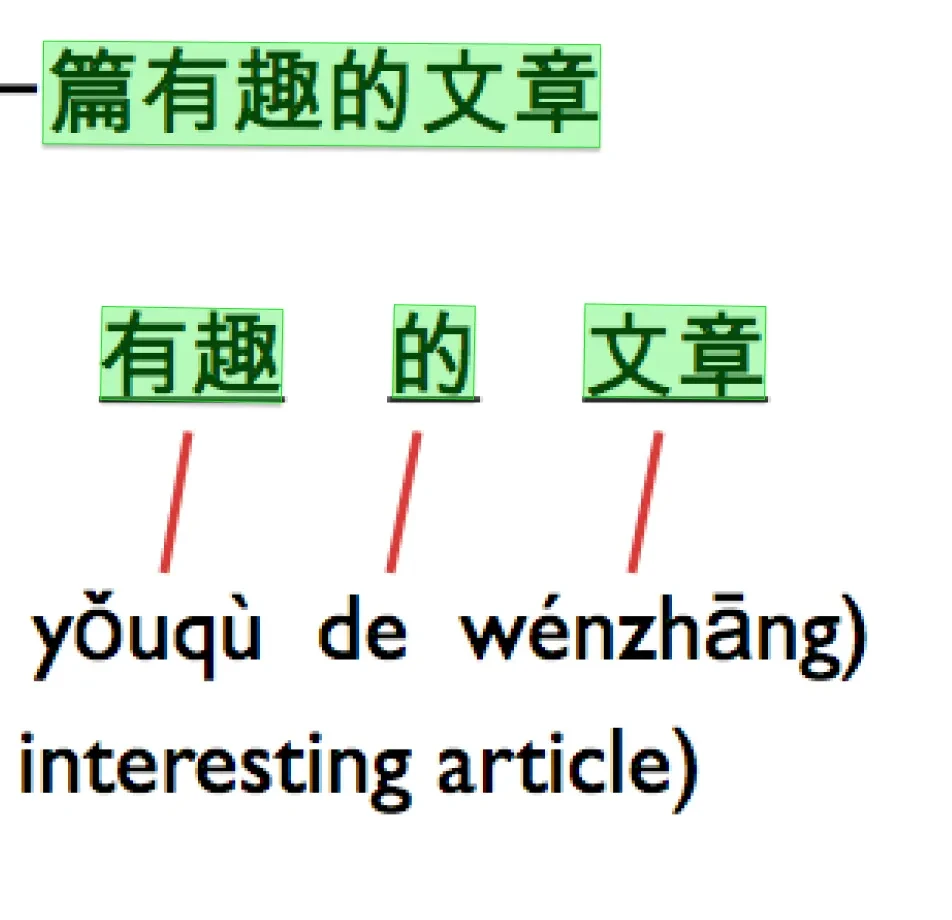
Data Collection Metrics
- Total Text Entries: 1,500,000
- News Articles: 400,000
- Literary Excerpts: 300,000
- Social Media Posts: 350,000
- Academic Papers: 250,000
- Everyday Conversations: 200,000
Annotation Process
Stages
- Text Pre-processing: Normalization, tokenization, and removal of irrelevant or sensitive information.
- Sentiment Analysis Annotation: Tagging texts as positive, neutral, or negative.
- Entity Recognition: Identifying and labeling entities such as names, places, and dates.
- Intent Recognition: Categorizing user intent, especially in conversational texts.
- Context Annotation: Capturing broader contextual information where relevant.
- Validation: Review by linguistic experts and utilizing preliminary NLU models.
Annotation Metrics
- Sentiment Annotations: 1,500,000
- Entity Annotations: 2,200,000 (Multiple entities can exist within one text entry)
- Intent Annotations: 200,000 (Primarily for conversational texts)
- Context Annotations: 1,000,000
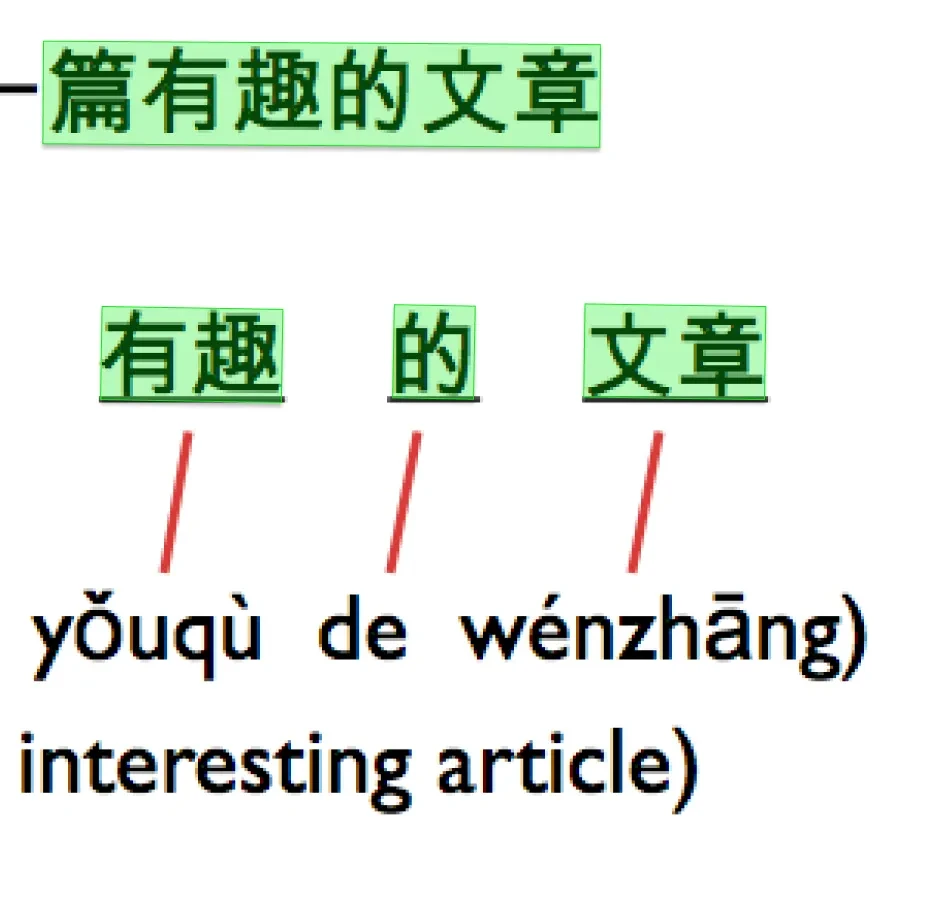



Quality Assurance
Stages
Automated NLU Model Verification: Early-stage NLU models assess the coherence and accuracy of annotations.
Peer Review: Subsequently, a secondary group of annotators checks a subset of the dataset for validation.
Inter-annotator Agreement: Furthermore, random texts are annotated by multiple individuals to confirm uniformity in understanding and labeling.
QA Metrics
- Annotations Validated using NLU Models: 750,000 (50% of total entries)
- Peer Reviewed Annotations: 450,000 (30% of total entries)
- Inconsistencies Identified and Rectified: 30,000 (2% of total entries)
Conclusion
The Chinese Natural Language Understanding Dataset is a monumental step towards bridging the gap between AI and the rich tapestry of the Chinese language. With its diverse content sources and meticulous annotations, the dataset is poised to revolutionize NLU applications for the vast Chinese-speaking population, ensuring that they receive intuitive, culturally-relevant, and linguistically accurate AI-driven solutions.

Quality Data Creation

Guaranteed TAT

ISO 9001:2015, ISO/IEC 27001:2013 Certified

HIPAA Compliance

GDPR Compliance

Compliance and Security
Let's Discuss your Data collection Requirement With Us
To get a detailed estimation of requirements please reach us.