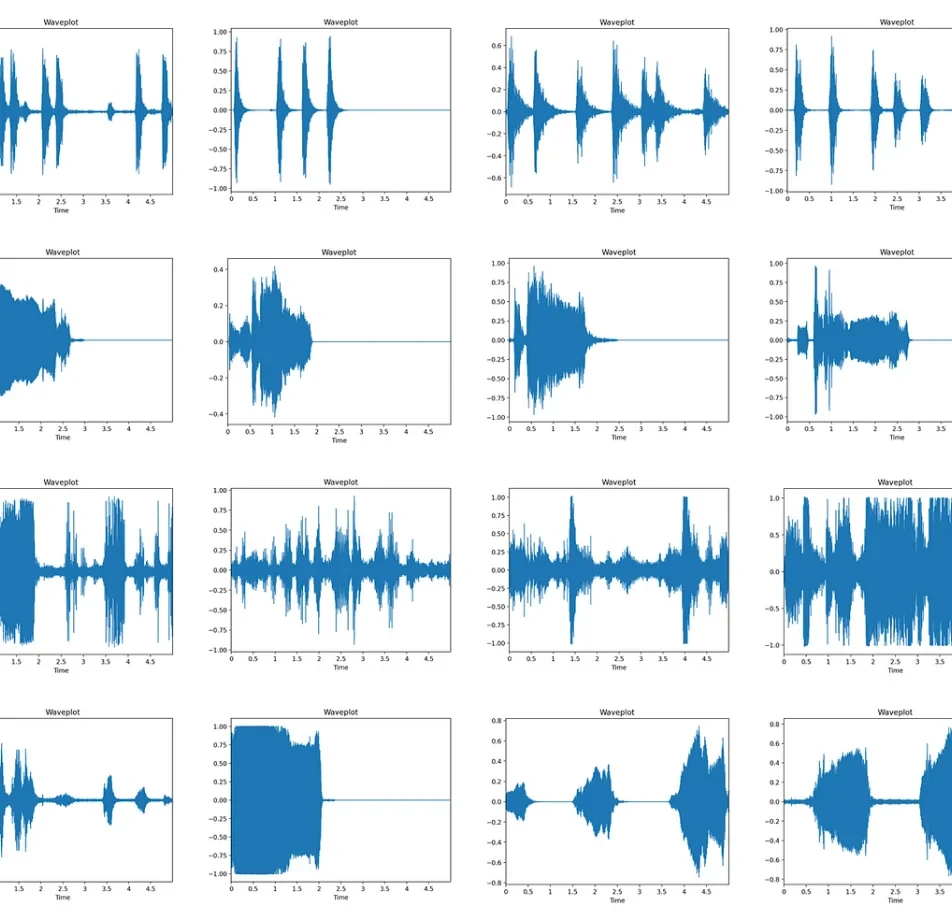
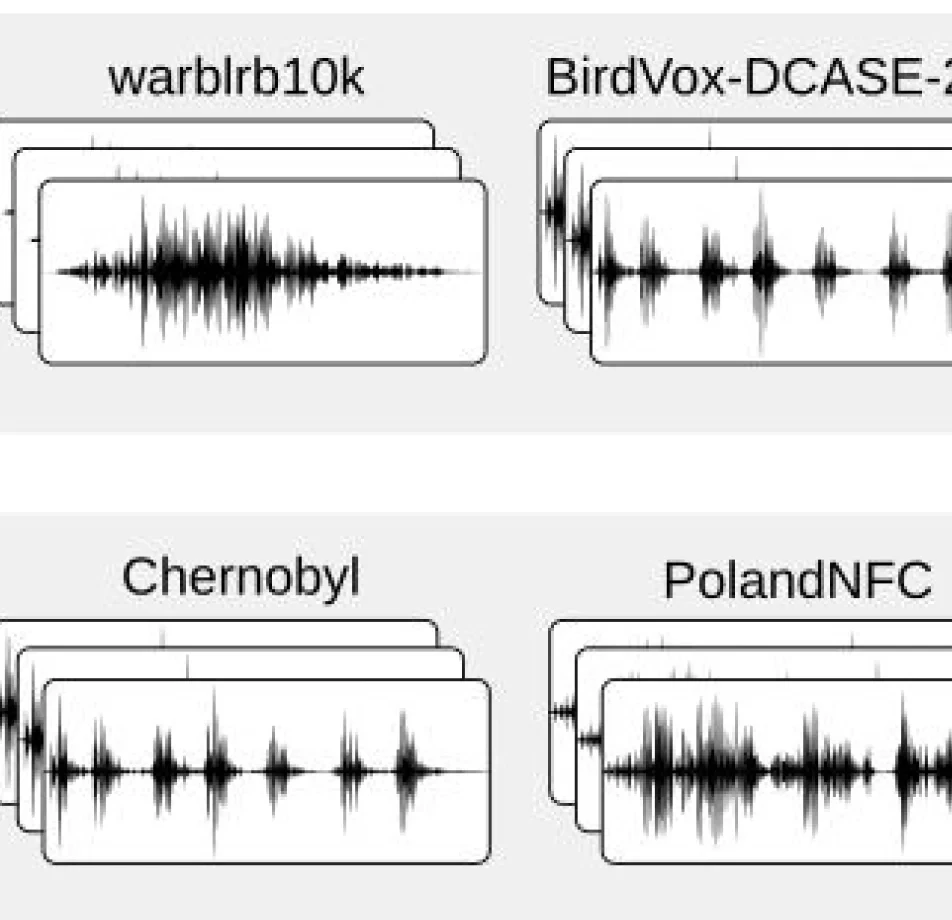
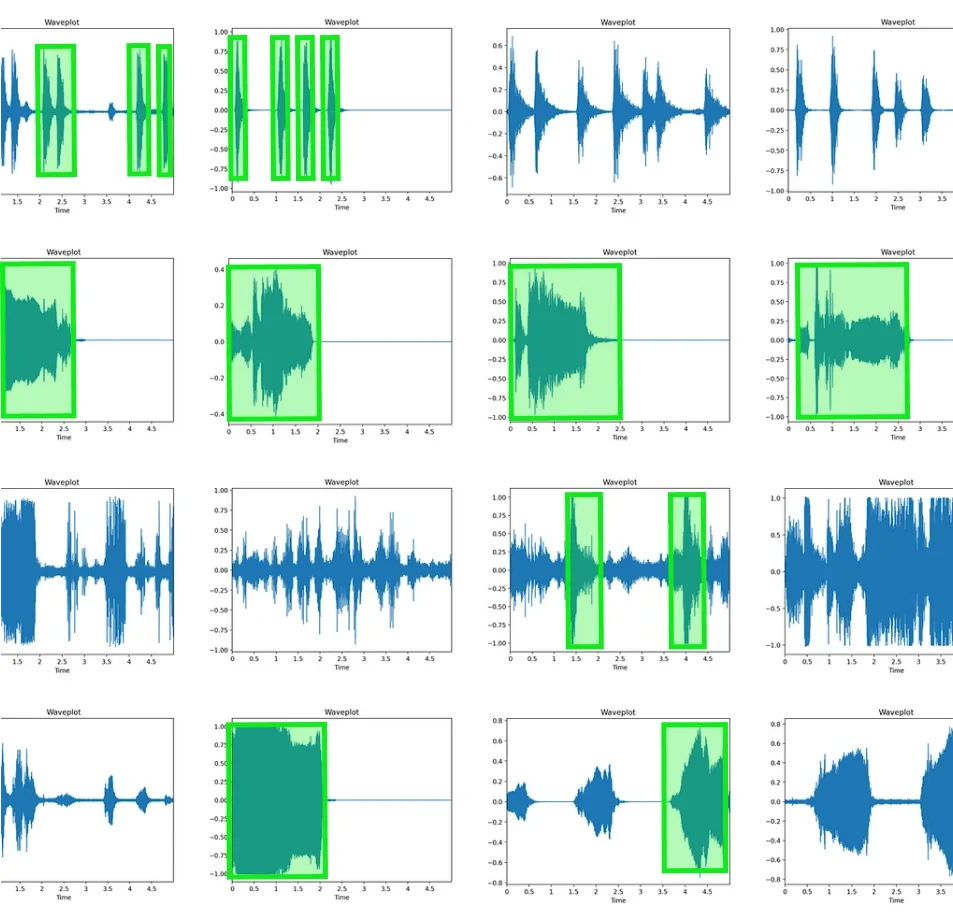
This ambitious undertaking, consequently, has yielded a robust audio dataset meticulously curated specifically for healthcare and conversational AI applications. Through meticulous collection and annotation, therefore, the dataset is poised to significantly bolster advancements in AI-driven healthcare solutions and conversational platforms alike.