
For AI and ML algorithms, data is the fuel that keeps them going. The processing of visual data by computers is inferior to that of human brains. For a computer to analyze data and make judgments, it has to be taught what it is analyzing and given context. These links are made by data annotation.
Identification and tagging of specific data, photos, and videos is a human-led job that enables computers to more easily recognize and categorize material, just like humans do, and to make predictions. ML algorithms cannot quickly compute the crucial features if data labeling is not done.
Data annotation is becoming a crucial component in creating reliable and effective machine learning models in the age of artificial intelligence (AI). we will learn about Data labeling and annotation, the method of annotating data for AI, the distinction between highly sought-after labeling experts and businesses offering data annotation services, and an overview of the various types of data annotation used in computer vision and natural language processing (NLP) in this blog.
What Data Annotation Is and Why It Matters?
By giving the data required for identifying patterns and making precise predictions, it plays a critical part in training machine learning algorithms. AI algorithms work best and produce the expected results when given properly labeled data.
Important benefits of using Data Annotation for AI and ML models
Smart technology and a smarter way of living are becoming a necessary component of our daily lives. Artificial Intelligence (AI) and Machine Learning (ML) enable everything from self-driving cars, clever and nudging email responses, forecasting arrival time through GPS apps, and the next music in the streaming queue. Data annotation makes it easier to comprehend the semantics of the objects, which improves algorithm performance.
Enhanced ML and AI model precision
When compared to images where some items have been accurately labeled or have not been labeled at all, a computer vision model performs with varying degrees of accuracy. Therefore, the model’s precision increases with improved annotation.
Accelerated model training
A data annotation firm used a video of a traffic light to identify and categorize automobiles and label them according to their category, model name, color, and direction they are moving in.
Simple labeling of datasets
It assisted a Swiss data analysis solutions provider in finding a solution to the problem of food waste for prestigious hotels and eateries.
End-user experience that is simplified
By offering pertinent advice, an effective intelligent product solves the issues and concerns of consumers.
Gives the capacity to scale up implementation
Annotating data allows for attitudes, intentions, and actions from various requests.
Significant categories of data labeling and annotation
Numerous types of data annotation are frequently employed, including:
Text annotation
With the use of tagging, search engines can quickly deliver the results that users are looking for by matching keywords with URLs in databases.
Annotations to videos
Technically, it separates a movie into frames, and each one distinctly identifies the object or objects of interest.
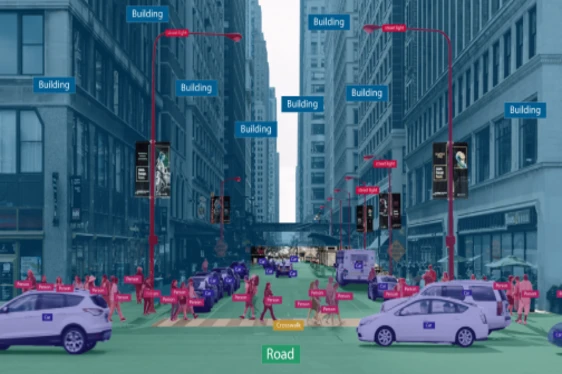
Image annotation
Image annotation is the process of labeling items of interest in an image dataset for machine learning using a variety of approaches, including bounding boxes, polygons, tracking, and masking.
Speech recognition with NLP annotation
The NLP annotation process, which includes Parts of Speech (POS) Tagging, Phonetic Annotation, Semantic Annotation, Key Phrase Tagging, Discourse Annotation, etc., captures characteristics of language structure. It enables ML systems to read meanings and comprehend circumstances similar to how humans do.
These steps cover every phase of the procedure, including gathering the data and exporting the annotated data for usage elsewhere.
The gathering of data
Data Collection for AI/ML models, including pictures, videos, audio recordings, and text, in one place is the initial stage in the data annotation process.
Preparing the data
Deskew pictures, format text, or transcribe video footage to standardize and improve the gathered data.
Choosing the appropriate tool or vendor
Based on the demands of your project, select a suitable data annotation tool or supplier. Platforms like V7 for picture annotation, Appen for video annotation, and Nanonets for document annotation are available as alternatives.
Directions for Annotation
To guarantee uniformity and accuracy throughout the process, establish specific instructions for annotators or annotation software.
Exporting data
Export the data in the desired format after finishing the data annotation. Platforms like Nanonets make it simple to transfer data to a variety of corporate software programs.
The Bottom Line
Now, as you understand the value of data annotation for projects involving machine learning and artificial intelligence. With insufficient training data sets, AI and ML are impossible to imagine.





